随着世界各个国家/地区纷纷制定人工智能相关法规,设计基于人工智能的系统的工程师必须满足这些新出台的规范和标准要求。在2023年10月30日,美国白宫也颁布了一项关于人工智能法规的行政命令,强调稳健的验证和确认(V&V)过程对基于人工智能的系统至关重要。该指令要求人工智能公司报告和测试特定模型,以确保人工智能系统按预期运行并满足指定要求。
人工智能法规和V&V过程将对安全关键型系统产生重大影响。人工智能越来越多地用于系统设计,包括汽车和航空航天工业等领域的安全关键型应用。
基于人工智能的系统中的验证和确认
验证旨在确定人工智能模型是否按照指定的要求设计和开发,而确认则是检查产品是否符合客户的要求和预期。通过采用 V&V 方法,工程师可以确保人工智能模型的输出符合规范,从而实现早期 Bug 检测并缓解数据偏向的风险。
在安全关键型系统中使用人工智能的一项优势是,人工智能模型可以模拟物理系统并验证设计。工程师可对基于人工智能的整个系统进行仿真,并使用数据在不同场景中测试系统,包括离群值事件。如果在安全关键型场景中执行 V&V,则可确保基于人工智能的安全关键型系统能够在各种情况下保持其性能水平。
大多数开发人工智能增强产品的行业,都要求工程师在产品上市前遵循相关标准。这些认证过程可确保此类产品中融入特定元素。工程师可执行 V&V 来测试这些元素的功能,这使得获得认证更容易。
在汽车行业中,ISO/CD PAS 8800 是一项拟制标准,旨在说明道路车辆的安全相关属性和风险因素。在航空航天和国防领域,认证是强制性要求。机载系统和设备认证中的软件考虑因素(DO178C)等现行标准不一定能直接帮助应对人工智能所带来的独特挑战。因此,新的 ARP6983 过程标准正在制定中,旨在为开发和认证实现人工智能的航空安全相关产品提供规范。
Deep Learning Toolbox™ Verification Library 和 MATLAB® Test™ 可以帮助工程师开发有助于遵循行业标准的软件,并简化大型系统中人工智能模型的验证和测试,从而使他们在航空和汽车领域的 V&V 方面保持领先地位。

航空航天工程团队使用基于模型的设计来管理和协调复杂的需求,自动生成代码,并严格测试模型和系统。
安全关键型系统中的 V&V 人工智能过程
在执行 V&V 时,工程师的目标是确保人工智能组件既能满足指定的要求,又能在各种工况下都表现出可靠性和安全性,因此可以随时部署。与人工智能相关的 V&V 过程涉及执行软件保证活动,其中包括静态和动态分析、测试、形式化方法和真实运营监控的组合。
各行各业的 V&V 过程可能略有不同,但 V&V 过程的主要步骤都包括:
l 分析决策过程以解决黑盒问题;
l 根据有代表性的数据集测试模型;
l 执行人工智能系统仿真;
l 确保模型在可接受的范围内运行。
下述 V&V 过程中的步骤是迭代步骤。随着工程师收集新数据、获得新深入信息和集成运行反馈,人工智能系统可以得到不断完善和改进。
分析决策过程以解决黑盒问题
在使用人工智能模型为系统添加自动化功能时,工程师会面临黑盒问题。理解基于人工智能的系统如何作出决策,对于提供透明度至关重要,因为这使工程师和科学家能够对模型预测建立信任并理解决策。
特征重要性分析方法可以帮助工程师确定哪些输入变量对模型预测的影响最大。这种分析方法的工作方式因模型(如基于树的模型和线性模型)而异,但是,一般过程会为每个输入变量赋予一个特征重要性分数。重要性分数越高,该特征对模型决策的影响就越大。对于汽车行业的安全关键型系统,变量可能包括环境因素,如降水或其他车辆的存在和行为。
可解释性方法有助于深入了解模型行为。当模型的黑盒性质使我们无法使用其他方法时,这种方法尤其重要。以图像为例,这些方法可用于识别图像中对最终预测贡献最大的区域。这样,工程师便可理解模型在做出预测时的主要关注点。
根据有代表性的数据集测试模型
通常,工程师会评估人工智能模型在真实场景中的性能,以确保安全关键型系统能够在这些场景中稳健运行。他们的目标是找出各种限制,以提高模型的准确度和可靠性。工程师首先会收集大量有代表性的真实数据集,并通过清洗数据使其适用于测试。然后,他们会设计测试用例来评估模型的各个方面,例如准确度和可再现性。最后,工程师会将模型应用于数据集,记录结果并将其与预期输出进行比较。模型设计将根据数据测试的结果进行改进。
执行人工智能系统仿真
凭借基于人工智能的系统仿真,工程师能够在受控环境中评估和评价系统的性能。在仿真期间,工程师会创建一个虚拟环境,以在各种条件下对真实系统进行模拟。首先,他们会定义仿真系统所需的输入和参数,例如初始条件和环境因素。然后,他们使用 Simulink® 等软件执行仿真,该软件会输出系统对建议场景的响应。与数据测试一样,仿真结果会与预期或已知结果进行比较,以便于模型得到逐步改进。
为了让人工智能模型安全可靠地运行,必须建立界限并监控模型的行为,以确保该模型在这些边界内运行。如果模型已基于有限的数据集训练,并在运行时遇到前所未见的数据,则会出现最常见的边界问题之一。同样,模型可能不够稳健,有可能导致不可预测的行为。
工程师采用缓解数据偏向和增强数据的方法,以确保人工智能模型在可接受的范围内运行。
缓解数据偏向的一种方法是,让用于训练人工智能模型的数据具有多变性,这有助于减少模型对限制其学习的重复模式的依赖。借助数据增强方法,可确保代表不同类别和人群的数据都能得到公平和平等的处理。在自动驾驶汽车场景中,数据增强可能涉及使用不同角度的行人照片来帮助模型检测行人,而不管这些行人的位姿如何。数据平衡方法通常与数据增强结合使用,包含来自每个数据类的相似样本。以行人为例,平衡数据意味着,针对每种不同的行人场景,如不同体型、服装样式、光照条件和背景,数据集都必须包含与之对应数量的图像。这种方法可以最大限度地减少偏向,并提高模型在各种现实情况下的泛化能力。
在安全关键型场景中部署神经网络时,稳健性是首要考虑因素。细微而难以察觉的变化会带来重大风险,使神经网络产生误分类。这些干扰可能会导致神经网络输出不正确或危险的结果。在错误可能导致灾难的系统中,这种情况尤其令人担忧。一种解决方案是,将形式化方法纳入开发和验证过程中。形式化方法就是使用严格的数学模型来确立和证明神经网络的正确性属性。通过应用这些方法,工程师可以提高网络对某些类型干扰的抵御能力,从而确保安全关键型应用具有更高的稳健性和可靠性。
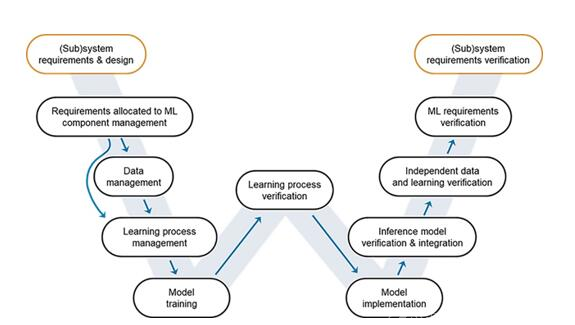
W 形开发过程是一种非线性 V&V 工作流,旨在确保人工智能模型的准确度和可靠性。
结束语
在基于人工智能的安全关键型系统时代,V&V 过程对于获得行业认证和遵循法律要求将变得至关重要。若要构建和维护值得信赖的系统,工程师需要采用验证方法,为运行这些系统的人工智能模型提供可解释性和透明度。随着工程师利用人工智能来帮助执行 V&V 过程,他们必须探索各种测试方法来应对人工智能技术所带来的日益复杂的挑战。在安全关键型系统中,这些工作可确保人工智能以负责且透明的方式得到使用。
作者:MathWorks 深度学习首席产品经理 Lucas Garcia 博士