深度学习吹响第三次AI浪潮的号角,从CNN到Transformer再到如今的大模型,AI的每次跃迁都在人类发展足迹中刻下烙印。
如今的大模型百花齐放,多模态、混合专家(MoE)推动AI走向通用人工智能,而下一次的跃迁,或许是将AI从云“拽”向端侧。
一方面是各种模型量化技术的成熟,另一方面是终端设备的各种异构集成计算架构的优化,释放了AI在端侧的能力和运行效率。
作为异构集成的算力一种——NPU,是平衡算力与功耗,保持量化模型后精度的核心算力硬件,凸显在端侧AI中的重要地位。

安谋科技近期召开了新品发布会,正式推出新一代NPU IP——“周易”X3,作为安谋科技“All in AI”产品战略下诞生的首款重磅产品,为应对端侧AI的升级需求,不光是性能上的一次全面升级,更是连携软件工具、开发套件等的生态层面的完整升级。
DSP+DSA架构,端侧AI计算效率新标杆
终端设备正承接AI赋能万物的概念,AI大模型的飞跃式发展,使得量化后的模型也具备了相当高的性能水平,哪怕在离线情况下,本地模型依旧能保持不错的交互体验。从多模态语音助手到实时图像生成,从智能座舱交互到辅助驾驶决策,端侧设备需要承载越来越复杂的AI计算任务。
然而端侧AI普遍面临几大问题:有限空间部署算力受限、能效要求高、带宽瓶颈大、开发门槛高等,如何平衡功耗和算力,利用有效的资源让模型能力得以释放,成为行业亟需突破的关键难题。
安谋科技选择从架构入手。
据安谋科技Arm China产品总监鲍敏祺介绍,“周易”X3基于专为大模型而生的DSP+DSA架构,从计算效率、带宽、精度适配、任务处理四大维度实现升级,解决端侧AI大模型运行难题。

安谋科技Arm China产品总监鲍敏祺
“周易”X3 NPU单Cluster最高支持4个Core,拥有8~80 FP8 TFLOPS算力且可灵活配置,单Core带宽高达256GB/s。
与以往量化模型中普遍使用的int整数格式不同,鲍敏祺特别提到,哪怕在端侧模型中,浮点计算也相较于定点计算有着优势,并且随着模型能力不断迭代,定点计算也将转向浮点计算,因此,在硬件层面也需要对浮点计算有着很好的支持,才能发挥出模型的能力。
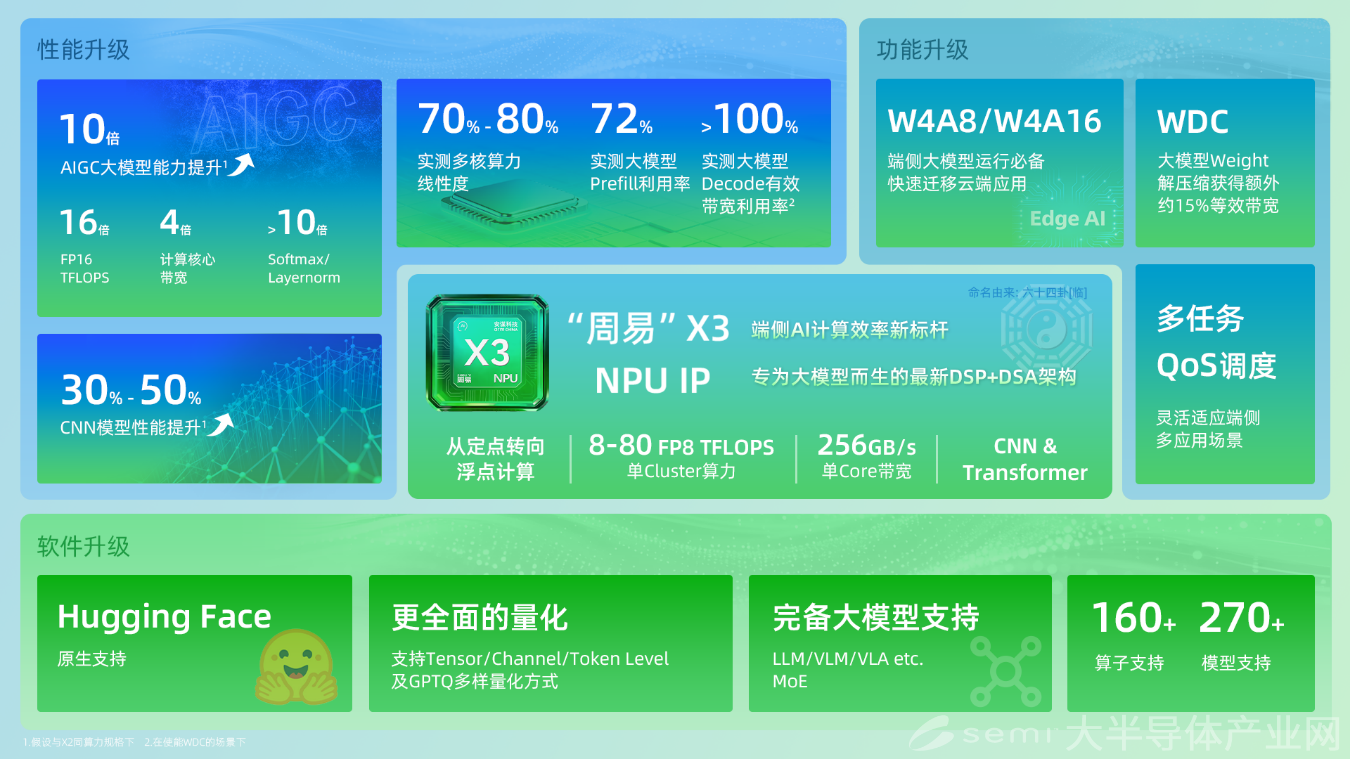
相较于“周易”X2产品,“周易”X3的CNN模型性能提升30%~50%,多核算力线性度达到70%~80%。在同算力规格下,AIGC大模型能力较上一代产品实现10倍增长,这得益于16倍的FP16 TFLOPS、4倍的计算核心带宽、超过10倍的Softmax和LayerNorm性能提升共同驱动。
借助这些优化,端侧大模型推理将更高效。
鲍敏祺表示,在Llama2 7B大模型实测中,“周易”X3 NPU IP在Prefill阶段算力利用率高达72%,并在自研的解压硬件WDC的加持下,实现Decode阶段有效带宽利用率超100%,远超行业平均水平,满足大模型解码阶段的高吞吐需求。
此外,“周易”X3在架构层面实现了多项创新,集成以下关键特性:
集成自研解压硬件WDC:使大模型Weight软件无损压缩后通过硬件解压能获得额外15%~20%等效带宽提升。
新增端侧大模型运行必备的W4A8/W4A16计算加速模式:对模型权重进行低比特量化,大幅降低带宽消耗,支持云端大模型向端侧的高效迁移。
集成AI专属硬件引擎AIFF(AI Fixed-Function)与专用硬化调度器:实现超低至0.5%的CPU负载与低调度延迟,灵活支持端侧多任务场景和任意优先级调度场景,确保高优先级任务的即时响应。
支持int4/int8/int16/int32/fp4/fp8/fp16/bf16/fp32多精度融合计算,强浮点计算:可灵活适配智能手机边缘部署、AI PC推理、智能汽车等从传统CNN到前沿大模型的数据类型需求,平衡性能与能效。
软硬协同,优化大模型端到端性能
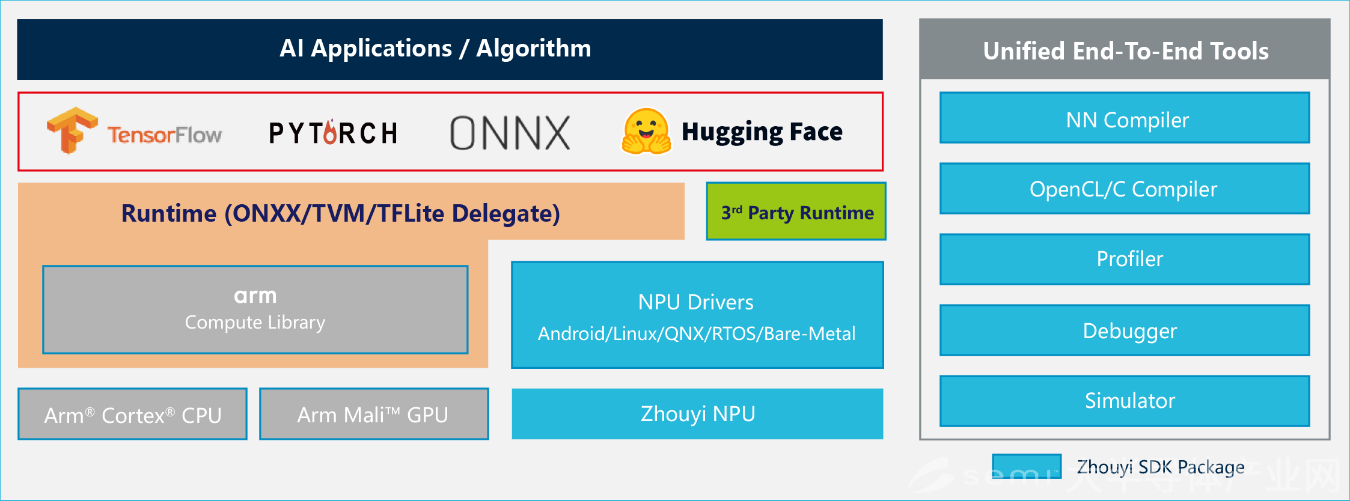
当前大模型多基于PyTorch、TensorFlow等主流框架开发,匹配的软件开发平台能实现NPU与这些框架的无缝对接。对开发者而言,无需重新编写底层代码,就能将大模型部署到NPU上。
具体到“周易”X3上,其搭载的Compass AI软件平台在发布初期就已支持超 160 种算子与270多种模型,广泛兼容TensorFlow、ONNX、PyTorch等主流AI框架,具备大模型动态Shape支持能力,并支持GPTQ等大模型主流量化方案、Hugging Face模型库,与LLM、VLM、VLA及MoE等模型。

安谋科技Arm China NPU产品线负责人兼首席架构师舒浩博士
安谋科技Arm China NPU产品线负责人兼首席架构师舒浩博士介绍称,Compass AI软件平台中的NN Compiler(神经网络编译器)集成Parser(模型解析)、Optimizer(优化器)、GBuilder(生成器)及AIPULLM(大模型运行工具),实现主流模型的高效转化、自动化优化与部署配置生成。
此外,Compass AI软件平台还提供多种开放接口,支持用户模型与自定义算子的开发与调试;配备丰富的调试工具与Bit精度软件仿真平台,支持多层次白盒开发与性能调优,极大简化算法移植与部署,并且支持Android、Linux、RTOS、QNX等多种操作系统,并通过TVM/ONNX实现SoC异构计算,高效调度CPU、GPU、NPU等计算资源。
“周易”NPU Compass AI软件平台
值得一提的是,Compass AI软件平台中的Parser、Optimizer、Linux Driver、TVM及内部IR格式等核心组件已相继开源,并拥有丰富的调试工具,且支持更易用的DSL算子编程语言。在此基础上,平台还赋予开发者更深度的定制能力:不仅可以使用平台中的Compiler、Debugger或DSL语言开发出自己的自定义算子,也可通过Parser、Optimizer等工具打造出属于自己的模型编译器,从而实现差异化设计与开发效率提升。
正因“周易”这一套软硬件的组合拳,新一代“周易”X3 NPU IP将端侧智能的边界拓展至更广阔的应用场景,面向基础设施、智能汽车、移动终端、智能物联网四大领域,匹配当前爆发的端侧AI需求,可广泛应用于加速卡、智能座舱、ADAS、具身智能、AI PC、AI手机、智能网关、智能IPC等AI设备,无论是各类大模型的适配能力,还是满足实时性的算力需求,“周易”的NPU都能轻松胜任。
“All in AI”,安谋科技的AI蓝图
自陈锋上任安谋科技CEO后,便重点聚焦于人工智能。他曾表示,安谋科技将公司自研“周易”NPU、“山海”SPU、“星辰”CPU及“玲珑”多媒体系列等IP产品与Arm通用计算单元深度融合,全面支持多场景AI应用规模部署,同时整合软硬件工具链,联动Arm及模型、算法、方案与终端厂商,共同构建扎根中国的AI创新生态,推进端侧和边缘侧AI落地。
而在此次“周易”发布会的现场,安谋科技也正式宣布了“All in AI”的产品战略以及“AI arm China”的战略发展方向。

安谋科技Arm China产品研发副总裁刘浩
安谋科技Arm China产品研发副总裁刘浩表示:“在‘All in AI’产品战略的指引下,我们将持续加大投入,以前瞻性视野整合顶尖研发资源,秉持开放合作理念,为生态伙伴提供业界领先的从硬件、软件到服务的端到端解决方案,全力赋能伙伴的产品创新和商业化落地。”
舒浩博士介绍了安谋科技NPU架构未来演进的方向,包括计算架构、通用计算能力、计算扩展能力、更多数据格式、高效的软件使用界面以及更开放的生态与合作模式。

活动现场,安谋科技系统展示了“周易”NPU产品家族的技术演进与落地成果,从“周易”Z1的基础感知到“周易”X3的复杂认知,从AIoT场景到AI终端大模型场景,这一技术演进路径清晰地表明,端侧AI正在从单一的功能实现,迈向融合多种模型、适应动态场景的“全民普及”新阶段。
周易“X3”的推出,进一步完善了安谋科技NPU IP产品家族在端侧AI领域的布局,也标志着安谋科技Arm China“All in AI”产品战略的正式开启。随着端侧AI能力的迭代,以及各类终端设备的推陈出新,属于安谋科技的AI时代新篇章正式拉开帷幕。